

Data mesh decentralizes data ownership, making data more scalable, accessible, and aligned with business domains. It enables the real-time, high-quality, and governed data foundation needed for agentic AI. For financial institutions, the focus is on evolving toward decision-ready data architectures that support intelligent, autonomous systems.
Across BFSI and other data-intensive industries, organizations are rapidly investing in AI, automation, and intelligent decision systems. The ambition is to move toward systems that can act, adapt, and decide in real time.
However, this ambition confronts a fundamental structural constraint.
Most of these AI initiatives are being built on top of data architectures that were never designed for autonomy. Traditional data platforms—data lakes and warehouses—were optimized for reporting and analytics, not for real-time, distributed intelligence.
This creates a fundamental mismatch.
Before organizations can scale agentic AI, they must address a more foundational question.
Is their data architecture built for autonomy, or is it still optimized for centralized control?
The Origin of Data Mesh and Its Foundational Shift
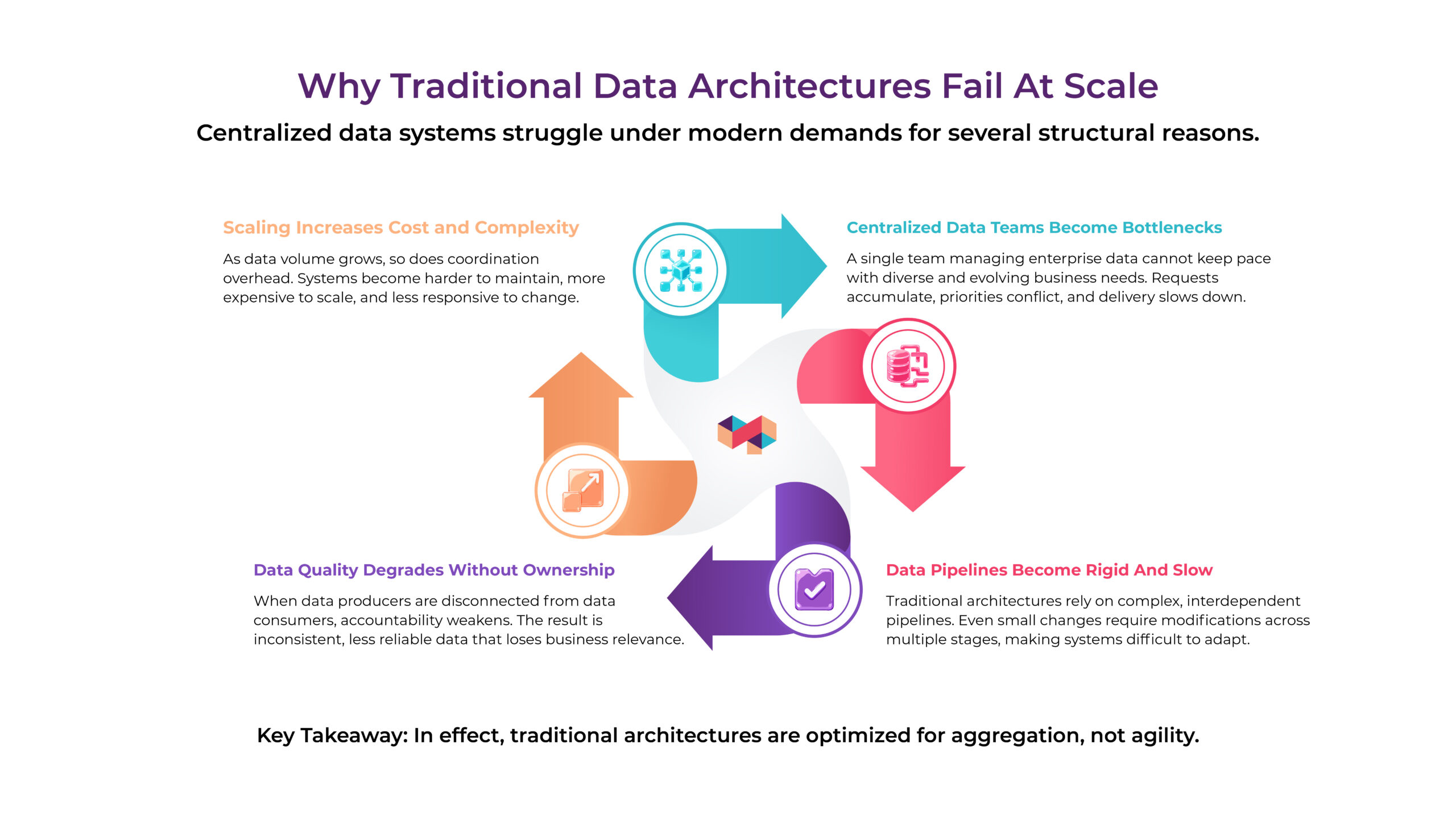
Data Mesh was introduced in 2019 by Zhamak Dehghani at Thoughtworks as a response to the growing failure of centralized data architectures. At a fundamental level, data mesh is a domain-driven approach that shifts data ownership from a centralized team to individual business domains, enabling teams to manage and share data as a product.
As organizations scaled, data became more complex and business-critical, but the operating model stayed the same—a central team managing ingestion, transformation, and access for the entire enterprise. This created bottlenecks, reduced responsiveness, and eroded data quality over time.
The real issue was not just technical, but structural. Data was centralized, while the business operated in distributed domains.
Data Mesh emerged from this gap. It shifts data ownership to domain teams and redefines data as a product that is designed for usability and consumption, not just storage and processing. In doing so, it aligns data architecture with how organizations function—through independent units that generate, understand, and use data in different ways.
The Core Principles of Data Mesh Architecture
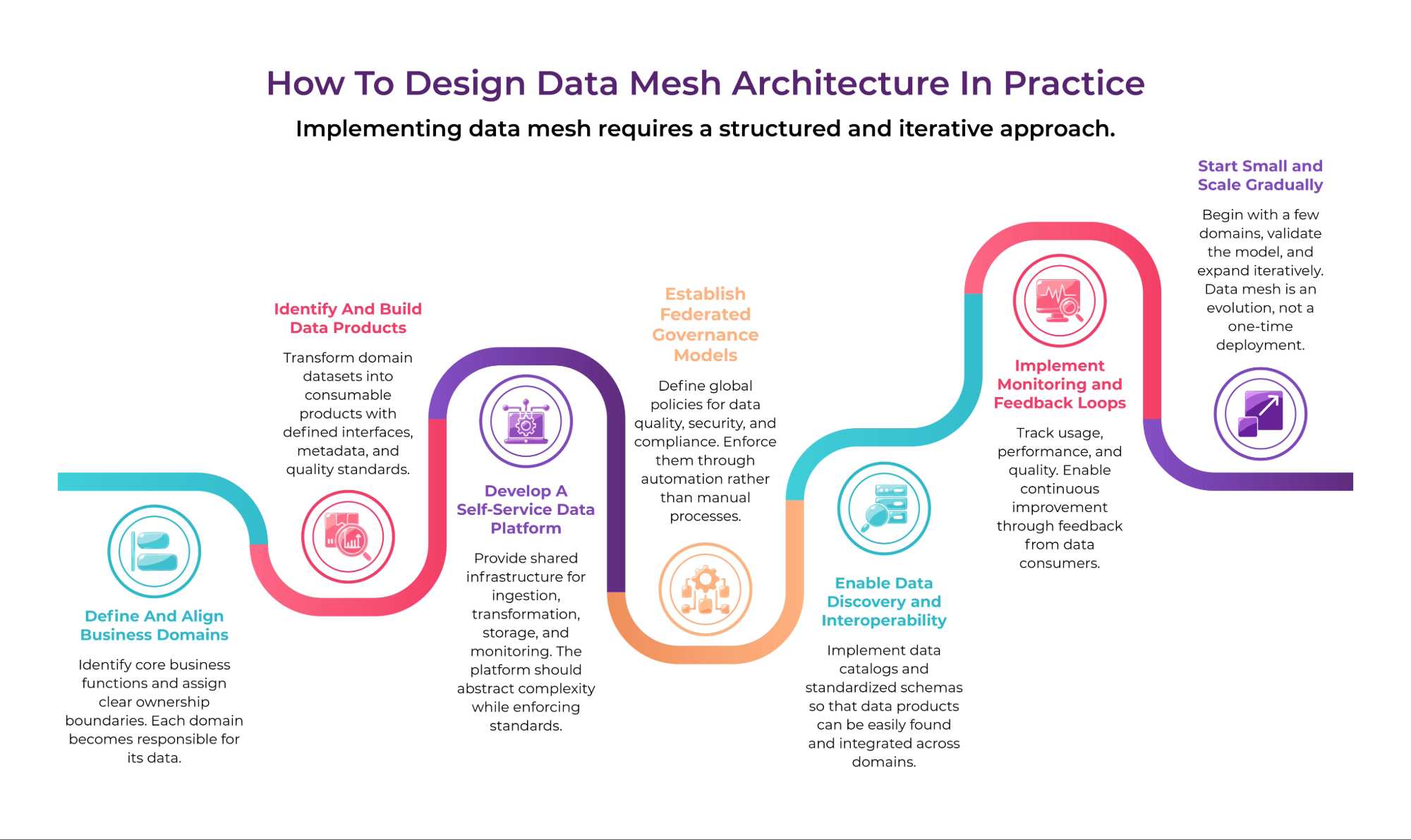
Four foundational data mesh principles redefine both architecture and operating model.
Domain Oriented Decentralization
Data ownership is aligned with business domains such as lending, payments, or customer operations. Teams closest to the data are responsible for managing and serving it.
Data As A Product
Each dataset is treated as a product with defined consumers. It must be:
- discoverable
- addressable
- trustworthy
- self-describing
This ensures usability, reliability, and long-term value.
Self Service Data Infrastructure
A shared platform provides the tools needed to build and manage data products. This enables domain teams to operate independently without duplicating infrastructure efforts.
Federated Computational Governance
Governance is applied through a combination of centralized standards and centralized enforcement. Policies around access, security, and quality are embedded into the system and enforced programmatically.
How Data Mesh Differs From Traditional Architectures
| Traditional Architecture | Data Mesh Architecture |
| Centralized data ownership | Domain-based data ownership |
| Data handled via pipelines | Data treated as a product |
| Heavy reliance on central platform | Self-service data infrastructure |
| Top-down governance | Federated governance |
| Control-driven operating model | Ownership-driven operating model |
Benefits Of Data Mesh Architecture in Modern Enterprises
Faster And More Relevant Data Access
Domain ownership enables quicker access to context-rich data without dependency on central teams.
Improved Data Quality and Accountability
Clear ownership ensures data is actively maintained, validated, and aligned with business meaning.
Scalable And Flexible Architecture
Decentralization allows systems to scale independently and adapt faster to changing business needs.
Stronger Business Alignment
Data is organized around domains, making it more usable, relevant, and actionable for decision-making.
Challenges And Trade Offs Of Data Mesh
Organizational And Cultural Shift
Transitioning to domain ownership requires changes in mindset, roles, and operating models.
Governance Complexity At Scale
Maintaining consistency across domains requires strong federated governance and standards.
Infrastructure And Investment Overhead
Building self-service platforms and enabling domain teams demands upfront effort and cost.
Risk Of Fragmentation Without Discipline
Without clear standards, decentralization can lead to inconsistency and reduced interoperability.
Data Mesh Vs Data Fabric
The debate around data fabric vs data mesh often creates confusion, as both address data challenges but in very different ways.
| Aspect | Data Fabric | Data Mesh |
| Core Focus | Data integration and connectivity | Data ownership and architectural restructuring |
| Approach | Connects existing systems without major structural change | Redesigns how data is owned, managed, and served |
| Ownership Model | Retains centralized or existing ownership | Decentralized, domain-based ownership |
| Primary Goal | Provide a unified view of data | Enable scalable, domain-driven data management |
| Implementation Layer | Technology layer on top of existing infrastructure | Organizational and architectural shift |
| Simple View | Connects data | Reorganizes data |
Why Data Mesh Becomes Foundational for Agentic AI
Agentic AI systems represent a shift from passive analytics to autonomous decision-making, where systems can act, trigger workflows, and continuously learn from outcomes. This shift significantly raises the bar for data.
These systems depend on real-time access to high-quality data, strong domain context, and built-in governance for traceability and control. Research from Gartner consistently highlights data latency, quality, and fragmentation as key barriers to scaling intelligent systems.
Traditional architectures struggle to meet these needs due to centralized pipelines and disconnected ownership models.
Data Mesh addresses this gap by decentralizing ownership, enabling real-time access from domain sources, and preserving business context within the data. Its federated governance model further ensures that autonomy is balanced with compliance and control.
As a result, Data Mesh aligns closely with the architectural requirements of Agentic AI, making it a strong foundation for building scalable and trustworthy autonomous systems.
Conclusion
Data mesh is not a mandatory architecture for every organization today. Most financial institutions will continue to operate hybrid models as they evolve beyond centralized systems.
However, the direction is clear. As data complexity increases and AI systems become more autonomous, organizations are moving toward decentralized ownership, real-time access, and product-oriented data thinking.
Across financial institutions, this shift is already visible. The focus is not on adopting data mesh in its purest form, but on building data foundations that can support continuous, intelligent decisioning.
Ultimately, the ability to scale agentic AI will depend on how well data architecture aligns with business domains, governance, and execution models.
At Anaptyss, this transformation is approached through a structured, domain-led model that brings together data, AI, and operating frameworks to enable truly decision-ready enterprises, delivered through DKO™.
Frequently Asked Questions
-
When should an organization consider moving to data mesh?
An organization should consider a transition when its centralized data team becomes a significant operational bottleneck, unable to handle analytical questions from management and product owners with the necessary speed. This often manifests as data engineers spending excessive time fixing broken pipelines caused by operational changes rather than delivering business value. A move to data mesh is most viable once an organization has already adopted domain-driven design and microservices, as these autonomous teams are best positioned to own their domain data. Ultimately, the shift is necessary when centralized, monolithic architectures fail to scale alongside the organization’s growth.
-
Is data mesh suitable for small or mid-sized organizations?
Generally, no. Data mesh is an architectural solution designed for large-scale complexity. There are specific prerequisites for adoption: you should have a modularized software system and a significant number—typically at least five—of independent domain teams already running systems in production. For smaller organizations, the administrative and technical overhead of building a self-serve platform and managing federated governance often outweighs the benefits. In these instances, a more integrated monolithic platform remains more efficient until the company reaches a scale where centralization actively inhibits agility.
-
What is the biggest challenge in implementing data mesh?
The primary hurdle is the profound cultural and organizational shift required to decentralize data ownership. Transitioning from a “push-and-ingest” model to a “serve-and-pull” framework requires domain teams to accept full accountability for their data products, which can be a difficult mindset change for those accustomed to a centralized team managing all data assets. Additionally, establishing federated governance requires a delicate balance between giving domains autonomy and enforcing global standards for security, interoperability, and compliance. Success depends on top management providing a clear vision and high-trust environment.
-
Can data mesh work with existing data lakes and warehouses?
Yes, a data mesh is not a replacement for these technologies but rather a new paradigm for how they are utilized. Existing traditional storage systems can power a data mesh by shifting their use from central monolithic repositories to decentralized storage used by individual domain teams for their specific data products. For example, a domain team might use a BigQuery dataset or S3 bucket as their “output port” to serve cleaned and processed analytical data. The critical change is organizational: the underlying infrastructure must support distributed ownership rather than central control.
-
How do you measure success in a data mesh model?
Success is measured through operational agility, product quality, and ecosystem growth. Key performance indicators include the lead time for creating new data products and the frequency with which these products are discovered and consumed by other domains. From a quality perspective, success is defined by a domain team’s ability to meet their Service-Level Objectives (SLOs) regarding data freshness, accuracy, and availability. Finally, success is evident when the “mesh” begins to form itself—where teams independently integrate multiple upstream data products to generate comprehensive reports and new insights.