

Credit risk modeling has evolved from basic statistical techniques to sophisticated AI and ML approaches. Pioneers like FitzPatrick and Altman introduced early models, while modern methods use algorithms such as ANNs, SVMs, KNN, decision trees, and hybrid models for accurate, flexible assessments. This blog explores these advancements, emphasizing their role in enhancing financial risk management.
Credit risk modeling is relatively a very old and essential component of financial risk management, where decisions cut across lending, investment, and regulatory practices.
In simpler terms, the history of credit risk modeling dates back to rudimentary statistical techniques.
Some of the pioneers in this area are FitzPatrick (1932) and Altman (1968), whose Z-score was one of the first quantitative models.
In this model, multivariate discriminant analysis was applied to predict bankruptcy through financial ratios.
This blog talks about modern approaches to credit risk modeling and recent advancements.
Modern AI and ML Approaches for Credit Risk Modeling
In recent years, artificial intelligence (AI) and machine learning (ML) have significantly revolutionized the process of credit risk modeling by providing accurate and flexible models.
Some of the algorithms and methodologies used in both consumer and corporate credit modeling, relying heavily on AI and ML, are as follows:
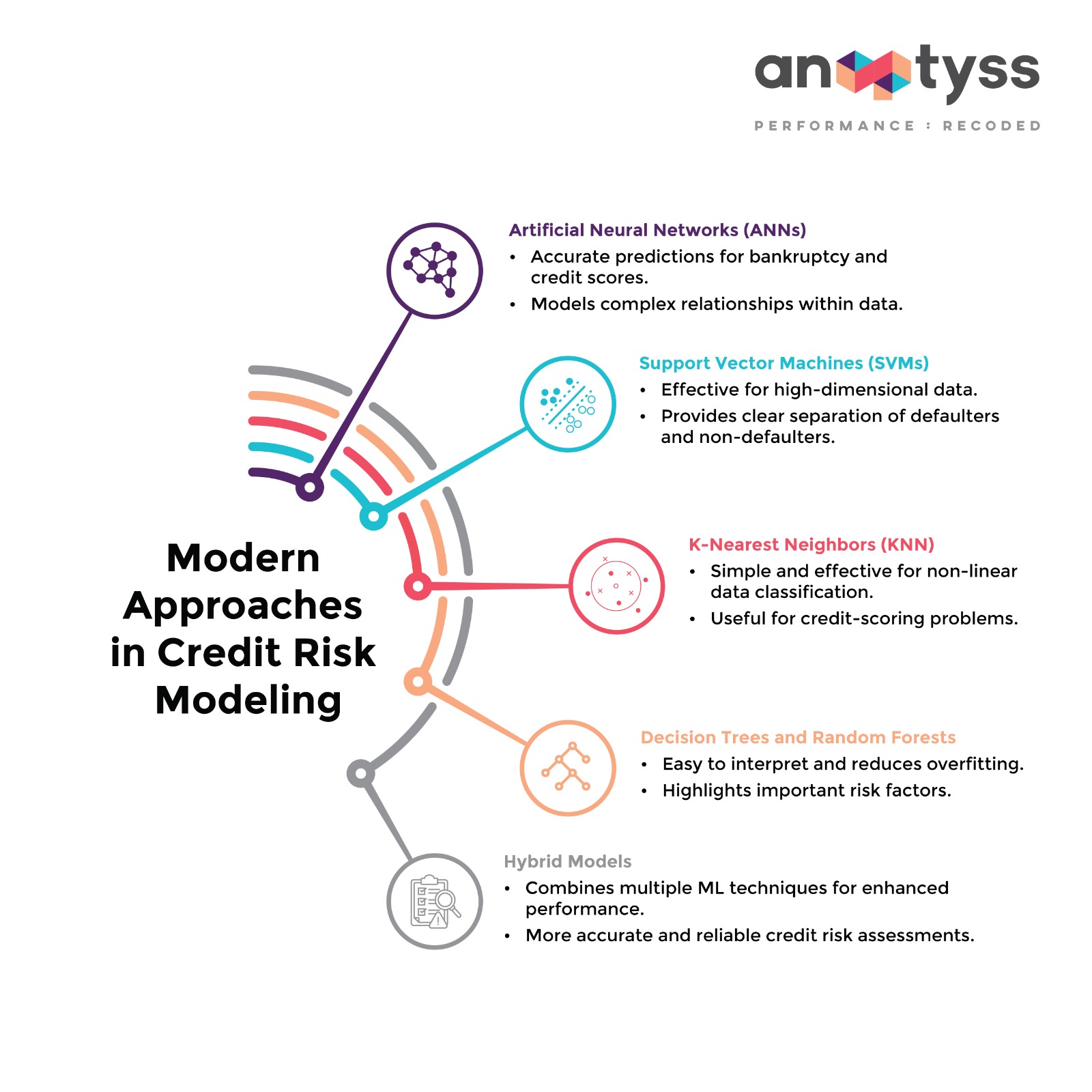
1. Artificial Neural Networks (ANNs)
Artificial Neural Networks is a network of many artificial neurons that are used to model complex and non-linear relationships within the data.
- Accurate Predictions
Great for predicting bankruptcy and credit scores. - Complex Relationships
Can model complex relationships within the data, helping banks better assess creditworthiness.
Used Cases:
- Identifying patterns and anomalies indicative of fraudulent transactions
- Analyze customer behavior to segment markets and tailor financial products.
2. Support Vector Machines (SVMs)
Credit risk modeling using the support vector machine (SVM) methodology works well by separating the defaulters from the non-defaulters.
This method works mathematically by setting a line (or boundary) that separates the two groups using a modified version of the data.
- High-Dimensional Data
Effective for analyzing high-dimensional data, enhancing the precision of risk assessments. - Clear Separation
Provides clear separation of classes, aiding in more reliable credit decisions.
Use Cases:
- Identifying trends and making investment decisions
- Predicting which customers are likely to leave, thereby enabling financial institutions to focus on retention strategies.
3. K-Nearest Neighbors (KNN)
KNN is a relatively simple, non-parametric technique in classification and regression; thus, it is easy to implement and interpret.
It is also equally effective in classifying non-linear distributions of datasets and is, therefore, a useful technique in most credit-scoring problems.
- Simplicity
Simple and easy to understand, making implementation straightforward. - Non-Linear Data
Effective for classifying non-linear data and improving the accuracy of credit scoring.
Used Cases:
- Build a recommender system that suggests financial products and services based on customer behavior and preferences
- Evaluate the risk profiles of new products and services.
4. Decision Trees and Random Forests
Decision trees for logic provide a graphical representation, and random forests provide many descriptions for the enhancement of prediction performance through logic representation.
On the other side, they tend to overfit the data.
- Intuitive
Easy to understand and interpret, facilitating clear decision-making processes.
Random forests solve the problem with the previous method because they aggregate the classification of many decision trees in the quest to improve accuracy and robustness.
- Reduced Overfitting
Enhances accuracy and robustness by reducing the risk of overfitting. - Variable Importance
Highlights important variables, helping banks identify key risk factors.
Used Cases
- Automation of loan approval process based on historical data.
- Management of investment or credit portfolios for better returns.
5. Hybrid Models
These models combine multiple machine learning techniques to enhance performance.
For instance, using genetic algorithms in the feature selection and, at the same time, tuning the parameters in order to maximize the accuracy of the support vector machines and other classifiers.
- Enhanced Performance
Maximizes the strengths of different models, leading to more accurate and reliable credit risk assessments.
Used Cases:
- Predict market trends and customer behavior more accurately by combining various.
- Integrating various predictive models to streamline operations and optimize processes.
Conclusion
Credit risk modeling, from classical statistical approaches to modern ones based on machine learning, has come a long way.
Modern techniques are more accurate, flexible, and scalable and have evolved into an essential tool in financial risk management. With the ever-advancing technology, credit risk modeling has become more sophisticated.
Anaptyss offers tailored solutions and expertise to build models that identify, quantify, and mitigate credit risks in line with regulatory standards.
Our expertise in financial modeling, risk management, and regulatory compliance enables practical and tailored solutions to manage credit risks and enhance financial institutions’ decision-making and operational efficiency.
To know more, reach us at: info@anaptyss.com.














